Функции случайных величин. Функция распределения вероятностей случайной величины и ее свойства
Случайной величиной называется переменная, которая может принимать те или иные значения в зависимости от различных обстоятельств, и случайная величина называется непрерывной , если она может принимать любое значение из какого-либо ограниченного или неограниченного интервала. Для непрерывной случайной величины невозможно указать все возможные значения, поэтому обозначают интервалы этих значений, которые связаны с определёнными вероятностями.
Примерами непрерывных случайных величин могут служить: диаметр детали, обтачиваемой до заданного размера, рост человека, дальность полёта снаряда и др.
Так как для непрерывных случайных величин функция F (x ), в отличие от дискретных случайных величин , нигде не имеет скачков, то вероятность любого отдельного значения непрерывной случайной величины равна нулю.
Это значит, что для непрерывной случайной величины бессмысленно говорить о распределении вероятностей между её значениями: каждое из них имеет нулевую вероятность. Однако в некотором смысле среди значений непрерывной случайной величины есть "более и менее вероятные". Например, вряд ли у кого-либо возникнет сомнение, что значение случайной величины - роста наугад встреченного человека - 170 см - более вероятно, чем 220 см, хотя и одно, и другое значение могут встретиться на практике.
Функция распределения непрерывной случайной величины и плотность вероятности
В качестве закона распределения, имеющего смысл только для непрерывных случайных величин, вводится понятие плотности распределения или плотности вероятности. Подойдём к нему путём сравнения смысла функции распределения для непрерывной случайной величины и для дискретной случайной величины.
Итак, функцией распределения случайной величины (как дискретной, так и непрерывной) или интегральной функцией называется функция , которая определяет вероятность, что значение случайной величины X меньше или равно граничному значению х .
Для дискретной случайной величины в точках её значений x 1 , x 2 , ..., x i ,... сосредоточены массы вероятностей p 1 , p 2 , ..., p i ,... , причём сумма всех масс равна 1. Перенесём эту интерпретацию на случай непрерывной случайной величины. Представим себе, что масса, равная 1, не сосредоточена в отдельных точках, а непрерывно "размазана" по оси абсцисс Оx с какой-то неравномерной плотностью. Вероятность попадания случайной величины на любой участок Δx будет интерпретироваться как масса, приходящаяся на этот участок, а средняя плотность на этом участке - как отношение массы к длине. Только что мы ввели важное понятие теории вероятностей: плотность распределения.
Плотностью вероятности f (x ) непрерывной случайной величины называется производная её функции распределения:
![]() .
.
Зная функцию плотности, можно найти вероятность того, что значение непрерывной случайной величины принадлежит закрытому интервалу [a ; b ]:

вероятность того, что непрерывная случайная величина X примет какое-либо значение из интервала [a ; b ], равна определённому интегралу от её плотности вероятности в пределах от a до b :
![]()
![]() .
.
При этом общая формула функции F (x ) распределения вероятностей непрерывной случайной величины, которой можно пользоваться, если известна функция плотности f (x ) :
![]() .
.
График плотности вероятности непрерывной случайной величины называется её кривой распределения (рис. ниже).

Площадь фигуры (на рисунке заштрихована), ограниченной кривой, прямыми, проведёнными из точек a и b перпендикулярно оси абсцисс, и осью Ох , графически отображает вероятность того, что значение непрерывной случайной величины Х находится в пределах от a до b .
Свойства функции плотности вероятности непрерывной случайной величины
1. Вероятность того, что случайная величина примет какое-либо значение из интервала (и площадь фигуры, которую ограничивают график функции f (x ) и ось Ох ) равна единице:
2. Функция плотности вероятности не может принимать отрицательные значения:
а за пределами существования распределения её значение равно нулю
Плотность распределения f (x ), как и функция распределения F (x ), является одной из форм закона распределения, но в отличие от функции распределения, она не универсальна: плотность распределения существует только для непрерывных случайных величин.
Упомянем о двух важнейших в практике видах распределения непрерывной случайной величины.
Если функция плотности распределения f (x ) непрерывной случайной величины в некотором конечном интервале [a ; b ] принимает постоянное значение C , а за пределами интервала принимает значение, равное нулю, то такое распределение называется равномерным .
Если график функции плотности распределения симметричен относительно центра, средние значения сосредоточены вблизи центра, а при отдалении от центра собираются более отличающиеся от средних (график функции напоминает разрез колокола), то такое распределение называется нормальным .
Пример 1. Известна функция распределения вероятностей непрерывной случайной величины:

Найти функцию f (x ) плотности вероятности непрерывной случайной величины. Построить графики обеих функций. Найти вероятность того, что непрерывная случайная величина примет какое-либо значение в интервале от 4 до 8: .
Решение. Функцию плотности вероятности получаем, находя производную функции распределения вероятностей:

График функции F (x ) - парабола:

График функции f (x ) - прямая:

Найдём вероятность того, что непрерывная случайная величина примет какое либо значение в интервале от 4 до 8:
Пример 2. Функция плотности вероятности непрерывной случайной величины дана в виде:

Вычислить коэффициент C . Найти функцию F (x ) распределения вероятностей непрерывной случайной величины. Построить графики обеих функций. Найти вероятность того, что непрерывная случайная величина примет какое-либо значение в интервале от 0 до 5: .
Решение. Коэффициент C найдём, пользуясь свойством 1 функции плотности вероятности:

Таким образом, функция плотности вероятности непрерывной случайной величины:

Интегрируя, найдём функцию F (x ) распределения вероятностей. Если x < 0 , то F (x ) = 0 . Если 0 < x < 10 , то
![]() .
.
x > 10 , то F (x ) = 1 .
Таким образом, полная запись функции распределения вероятностей:

График функции f (x ) :

График функции F (x ) :

Найдём вероятность того, что непрерывная случайная величина примет какое либо значение в интервале от 0 до 5:
Пример 3. Плотность вероятности непрерывной случайной величины X задана равенством , при этом . Найти коэффициент А , вероятность того, что непрерывная случайная величина X примет какое-либо значение из интервала ]0, 5[, функцию распределения непрерывной случайной величины X .
Решение. По условию приходим к равенству
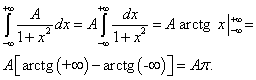
Следовательно, , откуда . Итак,
![]() .
.
Теперь находим вероятность того, что непрерывная случайная величина X примет какое-либо значение из интервала ]0, 5[:

Теперь получим функцию распределения данной случайной величины:

Пример 4.
Найти плотность вероятности непрерывной
случайной величины X
, которая принимает только неотрицательные значения, а
её функция распределения ![]() .
.
Даны определения Функции распределения случайной величины и Плотности вероятности непрерывной случайной величины. Эти понятия активно используются в статьях о статистике сайта . Рассмотрены примеры вычисления Функции распределения и Плотности вероятности с помощью функций MS EXCEL .
Введем базовые понятия статистики, без которых невозможно объяснить более сложные понятия.
Генеральная совокупность и случайная величина
Пусть у нас имеется генеральная совокупность (population) из N объектов, каждому из которых присуще определенное значение некоторой числовой характеристики Х.
Примером генеральной совокупности (ГС) может служить совокупность весов однотипных деталей, которые производятся станком.
Поскольку в математической статистике, любой вывод делается только на основании характеристики Х (абстрагируясь от самих объектов), то с этой точки зрения генеральная совокупность представляет собой N чисел, среди которых, в общем случае, могут быть и одинаковые.
В нашем примере, ГС - это просто числовой массив значений весов деталей. Х – вес одной из деталей.
Если из заданной ГС мы выбираем случайным образом один объект, имеющей характеристику Х, то величина Х является случайной величиной . По определению, любая случайная величина имеет функцию распределения , которая обычно обозначается F(x).
Функция распределения
Функцией распределения
вероятностей случайной величины
Х называют функцию F(x), значение которой в точке х равно вероятности события X F(x) = P(X Поясним на примере нашего станка. Хотя предполагается, что наш станок производит только один тип деталей, но, очевидно, что вес изготовленных деталей будет слегка отличаться друг от друга. Это возможно из-за того, что при изготовлении мог быть использован разный материал, а условия обработки также могли слегка различаться и пр. Пусть самая тяжелая деталь, произведенная станком, весит 200 г, а самая легкая - 190 г. Вероятность того, что случайно выбранная деталь Х будет весить меньше 200 г равна 1. Вероятность того, что будет весить меньше 190 г равна 0. Промежуточные значения определяются формой Функции распределения. Например, если процесс настроен на изготовление деталей весом 195 г, то разумно предположить, что вероятность выбрать деталь легче 195 г равна 0,5.
Типичный график Функции распределения
для непрерывной случайной величины приведен на картинке ниже (фиолетовая кривая, см. файл примера
): В справке MS EXCEL Функцию распределения
называют Интегральной
функцией распределения
(Cumulative
Distribution
Function
,
CDF
). Приведем некоторые свойства Функции распределения:
Напомним, что плотность распределения
является производной от функции распределения
, т.е. «скоростью» ее изменения: p(x)=(F(x2)-F(x1))/Dx при Dx стремящемся к 0, где Dx=x2-x1. Т.е. тот факт, что плотность распределения
>1 означает лишь, что функция распределения растет достаточно быстро (это очевидно на примере ). Примечание
: Площадь, целиком заключенная под всей кривой, изображающей плотность распределения
, равна 1. Примечание
: Напомним, что функцию распределения F(x) называют в функциях MS EXCEL интегральной функцией распределения
. Этот термин присутствует в параметрах функций, например в НОРМ.РАСП
(x; среднее; стандартное_откл; интегральная
). Если функция MS EXCEL должна вернуть Функцию распределения,
то параметр интегральная
, д.б. установлен ИСТИНА. Если требуется вычислить плотность вероятности
, то параметр интегральная
, д.б. ЛОЖЬ. Примечание
: Для дискретного распределения
вероятность случайной величине принять некое значение также часто называется плотностью вероятности (англ. probability mass function (pmf)). В справке MS EXCEL плотность вероятности
может называть даже "функция вероятностной меры" (см. функцию БИНОМ.РАСП()
). Понятно, что чтобы вычислить плотность вероятности
для определенного значения случайной величины, нужно знать ее распределение. Найдем плотность вероятности
для N(0;1) при x=2. Для этого необходимо записать формулу =НОРМ.СТ.РАСП(2;ЛОЖЬ)
=0,054 или =НОРМ.РАСП(2;0;1;ЛОЖЬ)
. Напомним, что вероятность
того, что непрерывная случайная величина
примет конкретное значение x равна 0. Для непрерывной случайной величины
Х можно вычислить только вероятность события, что Х примет значение, заключенное в интервале (а; b). 1) Найдем вероятность, что случайная величина, распределенная по (см. картинку выше), приняла положительное значение. Согласно свойству Функции распределения
вероятность равна F(+∞)-F(0)=1-0,5=0,5. НОРМ.СТ.РАСП(9,999E+307;ИСТИНА) -НОРМ.СТ.РАСП(0;ИСТИНА)
=1-0,5. 2) Найдем вероятность, что случайная величина, распределенная по , приняла отрицательное значение. Согласно определения Функции распределения,
вероятность равна F(0)=0,5. В MS EXCEL для нахождения этой вероятности используйте формулу =НОРМ.СТ.РАСП(0;ИСТИНА)
=0,5. 3) Найдем вероятность того, что случайная величина, распределенная по стандартному нормальному распределению
, примет значение, заключенное в интервале (0; 1). Вероятность равна F(1)-F(0), т.е. из вероятности выбрать Х из интервала (-∞;1) нужно вычесть вероятность выбрать Х из интервала (-∞;0). В MS EXCEL используйте формулу =НОРМ.СТ.РАСП(1;ИСТИНА) - НОРМ.СТ.РАСП(0;ИСТИНА)
. Все расчеты, приведенные выше, относятся к случайной величине, распределенной по стандартному нормальному закону
N(0;1). Понятно, что значения вероятностей зависят от конкретного распределения. В статье найти точку, для которой F(х)=0,5, а затем найти абсциссу этой точки. Абсцисса точки =0, т.е. вероятность, того что случайная величина Х примет значение <0, равна 0,5. В MS EXCEL используйте формулу =НОРМ.СТ.ОБР(0,5)
=0. Однозначно вычислить значение случайной величины
позволяет свойство монотонности функции распределения.
Обратная функция распределения
вычисляет , которые используются, например, при . Т.е. в нашем случае число 0 является 0,5-квантилем нормального распределения
. В файле примера
можно вычислить и другой квантиль
этого распределения. Например, 0,8-квантиль равен 0,84. В англоязычной литературе обратная функция распределения
часто называется как Percent Point Function (PPF). Примечание
: При вычислении квантилей
в MS EXCEL используются функции: НОРМ.СТ.ОБР()
, ЛОГНОРМ.ОБР()
, ХИ2.ОБР(),
ГАММА.ОБР()
и т.д. Подробнее о распределениях, представленных в MS EXCEL, можно прочитать в статье . СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
Пример 2.1.
Случайная величина X
задана функцией распределения Найти вероятность того, что в результате испытания X
примет значения, заключенные в промежутке (2,5; 3,6). Решение:
Х
в промежуток (2,5; 3,6) можно определить двумя способами: Пример 2.2.
При каких значениях параметров А
и В
функция F
(x
) = A + Be - x
может быть функцией распределения для неотрицательных значений случайной величины Х
. Решение:
Так как все возможные значения случайной величины Х
принадлежат интервалу , то для того, чтобы функция была функцией распределения для Х
, должно выполняться свойство: Ответ: Пример 2.3.
Случайная величина X задана функцией распределения Найти вероятность того, что в результате четырех независимых испытаний величина X
ровно 3 раза примет значение, принадлежащее интервалу (0,25;0,75). Решение:
Вероятность попадания величины Х
в промежуток (0,25;0,75) найдем по формуле: Пример 2.4.
Вероятность попадания мячом в корзину при одном броске равна 0,3. Составить закон распределения числа попаданий при трех бросках. Решение:
Случайная величина Х
– число попаданий в корзину при трех бросках – может принимать значения: 0, 1, 2, 3. Вероятности того, что Х
Х
: Пример 2.5.
Два стрелка делают по одному выстрелу в мишень. Вероятность попадания в нее первым стрелком равна 0,5, вторым – 0,4. Составить закон распределения числа попаданий в мишень. Решение:
Найдем закон распределения дискретной случайной величины Х
– числа попаданий в мишень. Пусть событие – попадание в мишень первым стрелком, а – попадание вторым стрелком, и - соответственно их промахи. Составим закон распределения вероятностей СВ Х
: Пример 2.6.
Испытываются 3 элемента, работающих независимо друг от друга. Длительности времени (в часах) безотказной работы элементов имеют функции плотности распределения: для первого: F
1 (t
) =1-e -
0,1 t
, для второго: F
2 (t
) = 1-e -
0,2 t
, для третьего: F
3 (t
) =1-e -
0,3 t
. Найти вероятность того, что в интервале времени от 0 до 5 часов: откажет только один элемент; откажут только два элемента; откажут все три элемента. Решение:
Воспользуемся определением производящей функции вероятностей : Вероятность того, что в независимых испытаниях, в первом из которых вероятность появления события А
равна , во втором и т. д., событие А
появится ровно раз, равна коэффициенту при в разложении производящей функции по степеням . Найдем вероятности отказа и неотказа соответственно первого, второго и третьего элемента в интервале времени от 0 до 5 часов: Составим производящую функцию: Коэффициент при равен вероятности того, что событие А
появится ровно три раза, то есть вероятности отказа всех трех элементов; коэффициент при равен вероятности того, что откажут ровно два элемента; коэффициент при равен вероятности того, что откажет только один элемент. Пример 2.7.
Дана плотность вероятности f
(x
)случайной величины X
: Найти функцию распределения F(x).
Решение:
Используем формулу: Таким образом, функция распределения имеет вид: Пример 2.8.
Устройство состоит из трех независимо работающих элементов. Вероятность отказа каждого элемента в одном опыте равна 0,1. Составить закон распределения числа отказавших элементов в одном опыте. Решение:
Случайная величина Х
– число элементов, отказавших в одном опыте – может принимать значения: 0, 1, 2, 3. Вероятности того, что Х
примет эти значения, найдем по формуле Бернулли: Таким образом, получаем следующий закон распределения вероятностей случайной величины Х
: Пример 2.9.
В партии из 6 деталей имеется 4 стандартных. Наудачу отобраны 3 детали. Составить закон распределения числа стандартных деталей среди отобранных. Решение:
Случайная величина Х
– число стандартных деталей среди отобранных – может принимать значения: 1, 2, 3 и имеет гипергеометрическое распределение. Вероятности того, что Х
где --
число деталей в партии; --
число стандартных деталей в партии; –
число отобранных деталей; --
число стандартных деталей среди отобранных. Пример 2.10.
Случайная величина имеет плотность распределения причем и не известны, но , а и . Найдите и . Решение:
В данном случае случайная величина X
имеет треугольное распределение (распределение Симпсона) на отрезке [a, b
]. Числовые характеристики X
: Следовательно, Ответ: Пример 2.11.
В среднем по 10% договоров страховая компания выплачивает страховые суммы в связи с наступлением страхового случая. Вычислить математическое ожидание и дисперсию числа таких договоров среди наудачу выбранных четырех. Решение:
Математическое ожидание и дисперсию можно найти по формулам: Возможные значения СВ (число договоров (из четырех) с наступлением страхового случая): 0, 1, 2, 3, 4. Используем формулу Бернулли, чтобы вычислить вероятности различного числа договоров (из четырех), по которым были выплачены страховые суммы: Ряд распределения СВ (число договоров с наступлением страхового случая) имеет вид: Ответ: , . Пример 2.12.
Из пяти роз две белые. Составить закон распределения случайной величины, выражающей число белых роз среди двух одновременно взятых. Решение:
В выборке из двух роз может либо не оказаться белой розы, либо может быть одна или две белые розы. Следовательно, случайная величина Х
может принимать значения: 0, 1, 2. Вероятности того, что Х
примет эти значения, найдем по формуле: где --
число роз; --
число белых роз; –
число одновременно взятых роз; --
число белых роз среди взятых. Тогда закон распределения случайной величины будет такой: Пример 2.13.
Среди 15 собранных агрегатов 6 нуждаются в дополнительной смазке. Составить закон распределения числа агрегатов, нуждающихся в дополнительной смазке, среди пяти наудачу выбранных из общего числа. Решение:
Случайная величина Х
– число агрегатов, нуждающихся в дополнительной смазке среди пяти выбранных – может принимать значения: 0, 1, 2, 3, 4, 5 и имеет гипергеометрическое распределение. Вероятности того, что Х
примет эти значения, найдем по формуле: где --
число собранных агрегатов; --
число агрегатов, нуждающихся в дополнительной смазке; –
число выбранных агрегатов; --
число агрегатов, нуждающихся в дополнительной смазке среди выбранных. Тогда закон распределения случайной величины будет такой: Пример 2.14.
Из поступивших в ремонт 10 часов 7 нуждаются в общей чистке механизма. Часы не рассортированы по виду ремонта. Мастер, желая найти часы, нуждающиеся в чистке, рассматривает их поочередно и, найдя такие часы, прекращает дальнейший просмотр. Найти математическое ожидание и дисперсию числа просмотренных часов. Решение:
Случайная величина Х
– число агрегатов, нуждающихся в дополнительной смазке среди пяти выбранных – может принимать значения: 1, 2, 3, 4. Вероятности того, что Х
примет эти значения, найдем по формуле: Тогда закон распределения случайной величины будет такой: Теперь вычислим числовые характеристики величины : Ответ: , . Пример 2.15.
Абонент забыл последнюю цифру нужного ему номера телефона, однако помнит, что она нечетная. Найти математическое ожидание и дисперсию числа сделанных им наборов номера телефона до попадания на нужный номер, если последнюю цифру он набирает наудачу, а набранную цифру в дальнейшем не набирает. Решение:
Случайная величина может принимать значения: . Так как набранную цифру абонент в дальнейшем не набирает, то вероятности этих значений равны . Составим ряд распределения случайной величины: Вычислим математическое ожидание и дисперсию числа попыток набора номера: Ответ: , . Пример 2.16.
Вероятность отказа за время испытаний на надежность для каждого прибора серии равна p
. Определить математическое ожидание числа приборов, давших отказ, если испытанию подверглись N
приборов. Решение:
Дискретная случайная величина X - число отказавших приборов в N
независимых испытаниях, в каждом из которых вероятность появления отказа равна p,
распределена по биномиальному закону. Математическое ожидание биномиального распределения равно произведению числа испытаний на вероятность появления события в одном испытании: Пример 2.17.
Дискретная случайная величина X
принимает 3 возможных значения: с вероятностью ; с вероятностью и с вероятностью . Найти и , зная, что M(X
) = 8. Решение:
Используем определения математического ожидания и закона распределения дискретной случайной величины: Находим: . Пример 2.18.
Отдел технического контроля проверяет изделия на стандартность. Вероятность того, что изделие стандартно, равна 0,9. В каждой партии содержится 5 изделий. Найти математическое ожидание случайной величины X
– числа партий, в каждой из которых содержится ровно 4 стандартных изделия, если проверке подлежат 50 партий. Решение:
В данном случае все проводимые опыты независимы, а вероятности того, что в каждой партии содержится ровно 4 стандартных изделия, одинаковы, следовательно, математическое ожидание можно определить по формуле: где - число партий; Вероятность того, что в партии содержится ровно 4 стандартных изделия. Вероятность найдем по формуле Бернулли: Ответ: Пример 2.19.
Найти дисперсию случайной величины X
– числа появлений события A
в двух независимых испытаниях, если вероятности появления события в этих испытаниях одинаковы и известно, что M
(X
) = 0,9. Решение:
Задачу можно решить двумя способами. 1) Возможные значения СВ X
: 0, 1, 2. По формуле Бернулли определим вероятности этих событий: ,
Тогда закон распределения X
имеет вид: Из определения математического ожидания определим вероятность : Найдем дисперсию СВ X
: 2) Можно использовать формулу: Ответ: Пример 2.20.
Математическое ожидание и среднее квадратическое отклонение нормально распределенной случайной величины X
соответственно равны 20 и 5. Найти вероятность того, что в результате испытания X
примет значение, заключенное в интервале (15; 25). Решение:
Вероятность попадания нормальной случайной величины Х
на участок от до выражается через функцию Лапласа: Пример 2.21.
Дана функция: При каком значении параметра C
эта функция является плотностью распределения некоторой непрерывной случайной величины X
? Найти математическое ожиданий и дисперсию случайной величины X
. Решение:
Для того, чтобы функция была плотностью распределения некоторой случайной величины , она должна быть неотрицательна, и она должна удовлетворять свойству: Следовательно: Вычислим математическое ожидание по формуле: Вычислим дисперсию по формуле: T
равна p
. Необходимо найти математическое ожидание и дисперсию этой случайной величины. Решение:
Закон распределения дискретной случайной величины X - числа появлений события в независимых испытаниях, в каждом из которых вероятность появления события равна , называют биномиальным. Математическое ожидание биномиального распределения равно произведению числа испытаний на вероятность появления события А одном испытании: Пример 2.25.
Производится три независимых выстрела по мишени. Вероятность попадания при каждом выстреле равна 0.25. Определить среднее квадратическое отклонение числа попаданий при трех выстрелах. Решение:
Так как производится три независимых испытания, и вероятность появления события А (попадания) в каждом испытании одинакова, то будем считать, что дискретная случайная величина X - число попаданий в мишень – распределена по биномиальному закону. Дисперсия биномиального распределения равна произведению числа испытаний на вероятности появления и непоявления события в одном испытании: Пример 2.26.
Среднее число клиентов, посещающих страховую компанию за 10 мин., равно трем. Найти вероятность того, что в ближайшие 5 минут придет хотя бы один клиент. Среднее число клиентов, пришедших за 5 минут: Пример 2.29.
Время ожидания заявки в очереди на процессор подчиняется показательному закону распределения со средним значением 20 секунд. Найти вероятность того, что очередная (произвольная) заявка будет ожидать процессор более 35 секунд. Решение:
В этом примере математическое ожидание Тогда искомая вероятность: Пример 2.30.
Группа студентов в количестве 15 человек проводит собрание в зале, в котором 20 рядов по 10 мест в каждом. Каждый студент занимает место в зале случайным образом. Какова вероятность того, что не более трех человек будут находиться на седьмом месте ряда? Решение:
Пример 2.31.
Тогда согласно классическому определению вероятности: где --
число деталей в партии; --
число нестандартных деталей в партии; –
число отобранных деталей; --
число нестандартных деталей среди отобранных. Тогда закон распределения случайной величины будет такой. Чтобы найти функции распределения случайных величин и их переменных, необходимо изучить все особенности данной области знаний. Существует несколько различных методов для нахождения рассматриваемых значений, включая изменение переменной и генерирование момента. Распределение - такое понятие, в основу которого легли такие элементы, как дисперсия, вариации. Однако они характеризуют только степень размаха рассеяния. Более важными функциями случайных величин являются те, которые связаны и независимы, и одинаково распределены. Например, если X1 - вес случайно выбранного индивидуума из популяции самцов, X2 - вес другого, ..., а Xn - вес еще одного человека из мужского населения, тогда, необходимо узнать, как случайная функция X распределяется. В этом случае применима классическая теорема, называемая центральной предельной. Она позволяет показать, что при больших n функция следует стандартным распределениям. Центральная предельная теорема предназначена для аппроксимации дискретных рассматриваемых значений, таких как биномиальное и Пуассона. Функции распределения случайных величин, рассматриваются, в первую очередь, на простых значениях одной переменной. Например, если X является непрерывной случайной величиной, имеющей собственное распределение вероятности. В данном случае исследуется, как найти функцию плотности Y, используя два разных подхода, а именно метод функции распределения и изменения переменной. Сначала рассматриваются только взаимно однозначные значения. Затем необходимо модифицировать технику изменения переменной, чтобы найти ее вероятность. Наконец, нужно узнать, как кумулятивного распределения может помочь моделировать случайные числа, которые следуют за определенными последовательными схемами. Метод функции распределения вероятностей случайной величины применим для того, чтобы найти ее плотность. При использовании этого способа вычисляется кумулятивное значение. Затем, дифференцируя его, можно получить плотность вероятности. Теперь, при наличии метода функции распределения, можно рассмотреть еще несколько примеров. Пусть X - непрерывная случайная величина с определенной плотностью вероятности. Какова функция плотности вероятности от x2? Если посмотреть или построить график функции (сверху и справа) у = х2, можно отметить, что она является возрастающей X и 0 В последнем примере большую осторожность использовали для индексирования кумулятивных функций и плотности вероятности либо с помощью X, либо с Y, чтобы указать, к какой случайной переменной они принадлежали. Например, при нахождении кумулятивной функции распределения Y получили X. Если необходимо найти случайную величину X и ее плотность, то ее просто нужно дифференцировать. Пусть X - непрерывная случайная величина заданная функцией распределения с общим знаменателем f (x). В этом случае, если поместить значение y в X = v (Y), то получится значение x, например v (y). Теперь, нужно получить функцию распределения непрерывной случайной величины Y. Где первое и второе равенство имеет место из определения кумулятивной Y. Третье равенство выполняется потому, что части функции, для которой u (X) ≤ y, также верно, что X ≤ v (Y). И последнее выполняется для определения вероятности в непрерывной случайной величине X. Теперь нужно взять производную от FY (y), кумулятивной функции распределения Y, чтобы получить плотность вероятности Y. Пусть X - непрерывная случайная величина с общим f (x), определенная над c1 Для решения этого вопроса можно собирать количественные данные и использовать эмпирическую кумулятивную функцию распределения. Обладая этой информацией и апеллируя ею, нужно комбинировать образцы средств, стандартные отклонения, медиаданные и так далее. Аналогично даже довольно простая вероятностная модель может иметь огромное количество результатов. Например, если перевернуть монету 332 раза. Тогда число получаемых результатов от переворотов больше, чем у google (10100) - число, но не менее 100 квинтиллионов раз выше элементарных частиц в известной вселенной. Не интересен анализ, который дает ответ на каждый возможный результат. Потребуется более простая концепция, такая как количество головок или самый длинный ход хвостов. Чтобы сосредоточить внимание на вопросах, представляющих интерес, принимается определенный результат. Определение в данном случае следующее: случайная величина является вещественной функцией с вероятностным пространством. Диапазон S случайной величины иногда называют пространством состояний. Таким образом, если X - рассматриваемое значение, то так N = X2, exp ↵X, X2 + 1, tan2 X, bXc и так далее. Последнее из них, округляя X до ближайшего целого числа, называют функцией пола. Как только определена интересующая функция распределения случайной величины х, вопрос обычно становится следующим: «Каковы шансы, что X попадает в какое-то подмножество значений B?». Например, B = {нечетные числа}, B = {больше 1} или B = {между 2 и 7}, чтобы указать эти результаты, которые имеют X, значение случайной величины, в подмножестве А. Таким образом, в приведенном выше примере можно описать события следующим образом. {X - нечетное число}, {X больше 1} = {X> 1}, {X находится между 2 и 7} = {2 Таким образом, можно вычислить вероятность того, что функция распределения случайной величины x примет значения в интервале путем вычитания. Необходимо подумать о включении или исключении конечных точек. Будем называть случайную переменную дискретной, если она имеет конечное или счетное бесконечное пространство состояний. Таким образом, X - число головок на трех независимых флипсах смещенной монеты, которая поднимается с вероятностью p. Нужно найти кумулятивную функцию распределения дискретной случайной величины FX для X. Пусть X - количество пиков в коллекции из трех карт. То Y = X3 через FX. FX начинается с 0, заканчивается на 1 и не уменьшается с увеличением значений x. Кумулятивная FX функция распределения дискретной случайной величины X является постоянной, за исключением прыжков. При скачке FX является непрерывной. Доказать утверждение о правильной непрерывности функции распределения из свойства вероятности можно с помощью определения. Звучит оно так: постоянная случайная величина имеет кумулятивную FX, которая дифференцируема. Чтобы показать, как это может произойти, можно привести пример: мишень с единичным радиусом. Предположительно. дротик равномерно распределяется на указанную область. Для некоторого λ> 0. Таким образом, функции распределения непрерывных случайных величин плавно увеличиваются. FX обладает свойствами функции распределения. Человек ждет автобуса на остановке, пока тот не прибудет. Решив для себя, что откажется, когда ожидание достигнет 20 минут. Здесь необходимо найти кумулятивную функцию распределения для T. Время, когда человек еще будет находиться на автовокзале или не уйдет. Несмотря на то, что кумулятивная функция распределения определена для каждой случайной величины. Все равно достаточно часто будут использоваться другие характеристики: масса для дискретной переменной и функция плотности распределения случайной величины. Обычно выводится значение через одно из этих двух значений. Эти значения рассматриваются следующими свойствами, которые имеют общий (массовый характер). Первое основано на том, что вероятности не отрицательны. Второе следует из наблюдения, что набор для всех x=2S, пространство состояний для X, образует разбиение вероятностной свободы X. Пример: броски необъективной монеты, результаты которой независимы. Можно продолжать выполнять определенные действия, пока не получится бросок голов. Пусть X обозначает случайную величину, которая дает количество хвостов перед первой головой. А p обозначает вероятность в любом заданном действии. Итак, массовая функция вероятности имеет следующие характерные признаки. Поскольку члены образуют численную последовательность, X называется геометрической случайной величиной. Геометрическая схема c, cr, cr2,. , crn имеет сумму. И, следовательно, sn имеет предел при n 1. В этом случае бесконечная сумма является пределом. Функция массы выше образует геометрическую последовательность с отношением. Следовательно, натуральных чисел a и b. Разность значений в функции распределения равна значению массовой функции. Рассматриваемые значения плотности имеют определение: X - случайная величина, распределение FX которой имеет производную. FX, удовлетворяющая Z xFX (x) = fX (t) dt-1, называется функцией плотности вероятности. А X называется непрерывной случайной величиной. В основной теореме исчисления функция плотности является производной распределения. Можно вычислить вероятности путем вычисления определенных интегралов. Поскольку собираются данные по нескольким наблюдениям, то должно рассматриваться более одной случайной величины за раз, чтобы моделировать экспериментальные процедуры. Следовательно, множество этих значений и их совместное распределение для двух переменных X1 и X2 означает просмотр событий. Для дискретных случайных величин определяются совместные вероятностные массовые функции. Для непрерывных рассматриваются fX1, X2, где совместная плотность вероятности удовлетворяется. Две случайные величины X1 и X2 независимы, если любые два связанных с ними события такие же. В словах вероятность того, что два события {X1 2 B1} и {X2 2 B2} происходят одновременно, y равно произведению переменных указанных выше, что каждая из них происходит индивидуально. Для независимых дискретных случайных величин имеется совместная вероятностная массовая функция, которая является произведением предельного объема ионов. Для непрерывных случайных величин являющихся независимыми, совместная функция плотности вероятности - произведение значений предельной плотности. В заключение рассматриваются n независимые наблюдения x1, x2,. , xn, возникающие из неизвестной плотности или массовой функции f. Например, неизвестный параметр в функциях для экспоненциальной случайной величины, описывающей время ожидания автобуса. Основная цель этой теоретической области - предоставить инструменты, необходимые для разработки умозаключительных процедур, основанных на обоснованных принципах статистической науки. Таким образом, одним из очень важных вариантов применения программного обеспечения является способность генерировать псевдоданные для имитации фактический информации. Это дает возможность тестировать и совершенствовать методы анализа перед необходимостью использования их в реальных базах. Это требуется для того, чтобы исследовали свойства данных посредством моделирования. Для многих часто используемых семейств случайных величин R предоставляет команды для их создания. Для других обстоятельств понадобятся методы моделирования последовательности независимых случайных величин, которые имеют общее распределение. Дискретные случайные переменные и образец Command. Команда sample используется для создания простых и стратифицированных случайных выборок. В результате, если вводится последовательность x, sample (x, 40) выбирает 40 записей из x таким образом, что все варианты размера 40 имеют одинаковую вероятность. Это использует команду R по умолчанию для выборки без замены. Можно использовать также для моделирования дискретных случайных величин. Для этого нужно предоставить пространство состояний в векторе x и массовой функции f. Вызов для replace = TRUE указывает, что сэмплирование происходит с заменой. Затем, чтобы дать образец из n независимых случайных величин, имеющих общую массовую функцию f, используется образец (x, n, replace = TRUE, prob = f). Определено, что 1 является наименьшим представленным значением, а 4 является наибольшим из всех. Если команда prob = f опущена, то образец будет выбирать равномерно из значений в векторе x. Проверить симуляцию против массовой функции, которая генерировала данные, можно обратив внимание на знак двойного равенства, ==. И пересчитав наблюдения, которые принимают каждое возможное значение для x. Можно сделать таблицу. Повторить это для 1000 и сравнить моделирование с соответствующей функцией массы. Сначала смоделировать однородные функции распределения случайных величин u1, u2,. , un на интервале . Около 10 % чисел должно находиться в пределах . Это соответствует 10 % симуляций на интервале для случайной величины с показанной функцией распределения FX. Точно так же около 10 % случайных чисел должно находиться в интервале . Это соответствует 10 % симуляций на интервале случайной величины с функцией распределения FX. Эти значения на x ось может быть получена из взятия обратной от FX. Если X - непрерывная случайная величина с плотностью fX, положительной всюду в своей области, то функция распределения строго возрастает. В этом случае FX имеет обратную функцию FX-1, известную как функция квантиля. FX (x) u только тогда, когда x FX-1 (u). Преобразование вероятности следует из анализа случайной переменной U = FX (X). FX имеет диапазон от 0 до 1. Он не может принимать значения ниже 0 или выше 1. Для значений u между 0 и 1. Если можно моделировать U, то необходимо имитировать случайную величину с распределением FX через функцию квантиля. Взять производную, чтобы увидеть, что плотность u варьируется в пределах 1. Поскольку случайная величина U имеет постоянную плотность по интервалу своих возможных значений, она называется равномерной на отрезке . Он моделируется в R с помощью команды runif. Идентичность называется вероятностным преобразованием. Видно, как оно работает в примере с дротильной доской. X между 0 и 1, функция распределения u = FX (x) = x2, и, следовательно, функция квантиля x = FX-1 (u). Можно моделировать независимые наблюдения расстояния от центра панели дротика, и создавая при этом равномерные случайные величины U1, U2,. , Un. Функция распределения и эмпирическая основаны на 100 симуляциях распределения дартс-доски. Для экспоненциальной случайной величины, предположительно u = FX (x) = 1 - exp (- x), и, следовательно, x = - 1 ln (1 - u). Иногда логика состоит из эквивалентных утверждений. В этом случае нужно объединить две части аргумента. Тождество с пересечением аналогично для всех 2 {S i i} S, вместо некоторого значения. Объединение Ci равно пространству состояний S и каждая пара взаимно исключена. Поскольку Bi - разбита на три аксиомы. Каждая проверка основана на соответствующей вероятности P. Для любого подмножества. Используя тождество, чтобы убедиться, что ответ не зависит от того, включены ли конечные точки интервала. Для каждого результата во всех событиях в конечном счете используется второе свойство непрерывности вероятностей, которое считается аксиоматическим. Закон распределения функции случайной величины здесь показывает, что каждой свое решение и ответ. Определение функции случайных величин. Функция дискретного случайного аргумента и ее числовые характеристики. Функция непрерывного случайного аргумента и ее числовые характеристики. Функции двух случайных аргументов. Определение функции распределения вероятностей и плотности для функции двух случайных аргументов.
При решении задач, связанных с оценкой точности работы различных автоматических систем, точности производства отдельных элементов систем и др., часто приходится рассматривать функции одной или нескольких случайных величин. Такие функции также являются случайными величинами. Поэтому при решении задач необходимо знать законы распределения фигурирующих в задаче случайных величин. При этом обычно известны закон распределения системы случайных аргументов и функциональная зависимость. Таким образом, возникает задача, которую можно сформулировать так. Дана система случайных величин (X_1,X_2,\ldots,X_n)
, закон распределения которой известен. Рассматривается некоторая случайная величина Y как функция данных случайных величин: Y=\varphi(X_1,X_2,\ldots,X_n).
Требуется определить закон распределения случайной величины Y
, зная вид функций (6.1) и закон совместного распределения ее аргументов. Рассмотрим задачу о законе распределения функции одного случайного аргумента Y=\varphi(X).
\begin{array}{|c|c|c|c|c|}\hline{X}&x_1&x_2&\cdots&x_n\\\hline{P}&p_1&p_2&\cdots&p_n\\\hline\end{array}
Тогда Y=\varphi(X)
также дискретная случайная величина с возможными значениями . Если все значения y_1,y_2,\ldots,y_n
различны, то для каждого k=1,2,\ldots,n
события \{X=x_k\}
и \{Y=y_k=\varphi(x_k)\}
тождественны. Следовательно, P\{Y=y_k\}=P\{X=x_k\}=p_k
\begin{array}{|c|c|c|c|c|}\hline{Y}&y_1=\varphi(x_1)&y_2=\varphi(x_2)&\cdots&y_n=\varphi(x_n)\\\hline{P}&p_1&p_2&\cdots&p_n\\\hline\end{array}
Если же среди чисел y_1=\varphi(x_1),y_2=\varphi(x_2),\ldots,y_n=\varphi(x_n)
есть одинаковые, то каждой группе одинаковых значений y_k=\varphi(x_k)
нужно отвести в таблице один столбец и соответствующие вероятности сложить. Для непрерывных случайных величин задача ставится так: зная плотность распределения f(x)
случайной величины X
, найти плотность распределения g(y)
случайной величины Y=\varphi(X)
. При решении поставленной задачи рассмотрим два случая. Предположим сначала, что функция y=\varphi(x)
является монотонно возрастающей, непрерывной и дифференцируемой на интервале (a;b)
, на котором лежат все возможные значения величины X
. Тогда обратная функция x=\psi(y)
существует, при этом являясь также монотонно возрастающей, непрерывной и дифференцируемой. В этом случае получаем G(y)=f\bigl(\psi(y)\bigr)\cdot |\psi"(y)|.
Пример 1.
Случайная величина X
распределена с плотностью F(x)=\frac{1}{\sqrt{2\pi}}e^{-x^2/2}
Найти закон распределения случайной величины Y
, связанной с величиной X
зависимостью Y=X^3
. Решение.
Так как функция y=x^3
монотонна на промежутке (-\infty;+\infty)
, то можно применить формулу (6.2). Обратная функция по отношению к функции \varphi(x)=x^3
есть \psi(y)=\sqrt{y}
, ее производная \psi"(y)=\frac{1}{3\sqrt{y^2}}
. Следовательно, G(y)=\frac{1}{3\sqrt{2\pi}}e^{-\sqrt{y^2}/2}\frac{1}{\sqrt{y^2}}
Рассмотрим случай немонотонной функции. Пусть функция y=\varphi(x)
такова, что обратная функция x=\psi(y)
неоднозначна, т. е. одному значению величины y
соответствует несколько значений аргумента x
, которые обозначим x_1=\psi_1(y),x_2=\psi_2(y),\ldots,x_n=\psi_n(y)
, где n
- число участков, на которых функция y=\varphi(x)
изменяется монотонно. Тогда G(y)=\sum\limits_{k=1}^{n}f\bigl(\psi_k(y)\bigr)\cdot |\psi"_k(y)|.
Пример 2.
В условиях примера 1 найти распределение случайной величины Y=X^2
. Решение.
Обратная функция x=\psi(y)
неоднозначна. Одному значению аргумента y
соответствуют два значения функции x
\begin{gathered}g(y)=f(\psi_1(y))|\psi"_1(y)|+f(\psi_2(y))|\psi"_2(y)|=\\\\=\frac{1}{\sqrt{2\pi}}\,e^{-\left(-\sqrt{y^2}\right)^2/2}\!\left|-\frac{1}{2\sqrt{y}}\right|+\frac{1}{\sqrt{2\pi}}\,e^{-\left(\sqrt{y^2}\right)^2/2}\!\left|\frac{1}{2\sqrt{y}}\right|=\frac{1}{\sqrt{2\pi{y}}}\,e^{-y/2}.\end{gathered}
Пусть случайная величина Y
является функцией двух случайных величин, образующих систему (X_1;X_2)
, т. е. Y=\varphi(X_1;X_2)
. Задача состоит в том, чтобы по известному распределению системы (X_1;X_2)
найти распределение случайной величины Y
. Пусть f(x_1;x_2)
- плотность распределения системы случайных величин (X_1;X_2)
. Введем в рассмотрение новую величину Y_1
, равную X_1
, и рассмотрим систему уравнений Будем полагать, что эта система однозначно разрешима относительно x_1,x_2
Плотность распределения случайной величины Y
G_1(y)=\int\limits_{-\infty}^{+\infty}f(x_1;\psi(y;x_1))\!\left|\frac{\partial\psi(y;x_1)}{\partial{y}}\right|dx_1.
Заметим, что рассуждения не изменяются, если введенную новую величину Y_1
положить равной X_2
. На практике часто встречаются случаи, когда нет особой надобности полностью определять закон распределения функции случайных величин, а достаточно только указать его числовые характеристики. Таким образом, возникает задача определения числовых характеристик функций случайных величин помимо законов распределения этих функций. Пусть случайная величина Y
является функцией случайного аргумента X
с заданным законом распределения Y=\varphi(X).
Требуется, не находя закона распределения величины Y
, определить ее математическое ожидание M(Y)=M[\varphi(X)].
Пусть X
- дискретная случайная величина, имеющая ряд распределения \begin{array}{|c|c|c|c|c|}\hline{x_i}&x_1&x_2&\cdots&x_n\\\hline{p_i}&p_1&p_2&\cdots&p_n\\\hline\end{array}
Составим таблицу значений величины Y
и вероятностей этих значений: \begin{array}{|c|c|c|c|c|}\hline{y_i=\varphi(x_i)}&y_1=\varphi(x_1)&y_2=\varphi(x_2)&\cdots&y_n=\varphi(x_n)\\\hline{p_i}&p_1&p_2&\cdots&p_n\\\hline\end{array}
Эта таблица не является рядом распределения случайной величины Y
, так как в общем случае некоторые из значений могут совпадать между собой и значения в верхней строке не обязательно идут в возрастающем порядке. Однако математическое ожидание случайной величины Y
можно определить по формуле M[\varphi(X)]=\sum\limits_{i=1}^{n}\varphi(x_i)p_i,
Формула (6.4) не содержит в явном виде закон распределения самой функции \varphi(X)
, а содержит только закон распределения аргумента X
. Таким образом, для определения математического ожидания функции Y=\varphi(X)
вовсе не требуется знать закон распределения функции \varphi(X)
, а достаточно знать закон распределения аргумента X
. Для непрерывной случайной величины математическое ожидание вычисляется по формуле M[\varphi(X)]=\int\limits_{-\infty}^{+\infty}\varphi(x)f(x)\,dx,
Рассмотрим случаи, когда для нахождения математического ожидания функции случайных аргументов не требуется знание даже законов распределения аргументов, а достаточно знать только некоторые их числовые характеристики. Сформулируем эти случаи в виде теорем. Теорема 6.1.
Математическое ожидание суммы как зависимых, так и независимых двух случайных величин равно сумме математических ожиданий этих величин:
M(X+Y)=M(X)+M(Y).
Теорема 6.2.
Математическое ожидание произведения двух случайных величин равно произведению их математических ожиданий плюс корреляционный момент:
M(XY)=M(X)M(Y)+\mu_{xy}.
Следствие 6.1.
Математическое ожидание произведения двух некоррелированных случайных величин равно произведению их математических ожиданий.
Следствие 6.2.
Математическое ожидание произведения двух независимых случайных величин равно произведению их математических ожиданий.
По определению дисперсии имеем D[Y]=M[(Y-M(Y))^2].
. Следовательно, D[\varphi(x)]=M[(\varphi(x)-M(\varphi(x)))^2]
, где . Приведем расчетные формулы только для случая непрерывных случайных аргументов. Для функции одного случайного аргумента Y=\varphi(X)
дисперсия выражается формулой D[\varphi(x)]=\int\limits_{-\infty}^{+\infty}(\varphi(x)-M(\varphi(x)))^2f(x)\,dx,
где M(\varphi(x))=M[\varphi(X)]
- математическое ожидание функции \varphi(X)
; f(x)
- плотность распределения величины X
. Формулу (6.5) можно заменить на следующую: D[\varphi(x)]=\int\limits_{-\infty}^{+\infty}\varphi^2(x)f(x)\,dx-M^2(X)
Рассмотрим теоремы о дисперсиях
, которые играют важную роль в теории вероятностей и ее приложениях. Теорема 6.3.
Дисперсия суммы случайных величин равна сумме дисперсий этих величин плюс удвоенная сумма корреляционных моментов каждой из слагаемых величин со всеми последующими: D\!\left[\sum\limits_{i=1}^{n}X_i\right]=\sum\limits_{i=1}^{n}D+2\sum\limits_{i Следствие 6.3.
Дисперсия суммы некоррелированных случайных величин равна сумме дисперсий слагаемых: D\!\left[\sum\limits_{i=1}^{n}X_i\right]=\sum\limits_{i=1}^{n}D
\mu_{y_1y_2}= M(Y_1Y_2)-M(Y_1)M(Y_2).
\mu_{y_1y_2}=M(\varphi_1(X)\varphi_2(X))-M(\varphi_1(X))M(\varphi_2(X)).
Рассмотрим основные свойства корреляционного момента и коэффициента корреляции
. Свойство 1.
От прибавления к случайным величинам постоянных величин корреляционный момент и коэффициент корреляции не изменяются. Свойство 2.
Для любых случайных величин X
и Y
абсолютная величина корреляционного момента не превосходит среднего геометрического дисперсий данных величин: |\mu_{xy}|\leqslant\sqrt{D[X]\cdot D[Y]}=\sigma_x\cdot \sigma_y,
Вычисление плотности вероятности с использованием функций MS EXCEL
Вычисление вероятностей с использованием функций MS EXCEL
Вместо +∞ в формулу введено значение 9,999E+307= 9,999*10^307, которое является максимальным числом, которое можно ввести в ячейку MS EXCEL (так сказать, наиболее близкое к +∞).

![]() .
.![]() .
.

![]() .
.

![]() .
.![]() .
.![]() .
.

![]() . Решая данную систему, получим две пары значений: . Так как по условию задачи , то окончательно имеем:
. Решая данную систему, получим две пары значений: . Так как по условию задачи , то окончательно имеем: ![]() .
.![]() .
.![]() .
.![]() .
.
0,6561
0,2916
0,0486
0,0036
0,0001
![]() .
.![]() .
.![]() .
.
![]() .
.![]() .
.![]() .
.![]() .
.![]() .
.![]() .
.
![]() .
.![]() .
.![]() .
.![]() .
.
0,2

![]() ,
,![]() .
.![]() ,
.
,
.
![]() .
.![]() .
.![]() .
.
![]() .
.
![]() .
.![]() .
.![]()
![]()
![]() . .
. .
![]() , а интенсивность отказов равна .
, а интенсивность отказов равна .
Функции одной случайной переменной
Методика распределения рассматриваемых значений
Техника смены переменных

Обобщение для функции уменьшения
Функции распределения

Случайные переменные и функции распределения

Массовые функции
Независимые случайные переменные

Имитация случайных переменных
Иллюстрирование трансформации вероятности


Экспоненциальная функция и ее переменные
Закон распределения вероятностей функции одной случайной величины
и искомый ряд распределения имеет вид
Применяя формулу (6.3), получаем:
Закон распределения функции двух случайных величин
и удовлетворяет условиям дифференцируемости.Математическое ожидание функции случайных величин
так как величина, определяемая формулой (6.4), не может измениться от того, что под знаком суммы некоторые члены будут заранее объединены, а порядок членов изменен.
где f(x)
- плотность распределения вероятностей случайной величины X
.Дисперсия функции случайных величин
т. е. корреляционный момент двух функций случайных величин равен математическому ожиданию произведения этих функций минус произведение из математических ожиданий.